Top Code Documentation Best Practices for Clear, Effective Docs


Writing Stellar Code Documentation: Why It Matters
This listicle presents code documentation best practices to elevate your software projects. Learn how to write clear, concise, and effective documentation that saves time and reduces headaches. We'll cover practical techniques, from writing self-documenting code and leveraging API documentation to generating documentation automatically and managing README files. Mastering these code documentation best practices improves code maintainability, simplifies onboarding, and reduces errors. Let's dive in.
1. Write Self-Documenting Code
One of the most fundamental code documentation best practices is writing self-documenting code. This approach prioritizes making the code itself readily understandable without relying heavily on external documentation. Instead of explaining what the code does through separate comments or documents, self-documenting code reveals its intent and functionality directly through its structure and naming conventions. This minimizes the risk of documentation becoming outdated or inaccurate, as the code itself serves as the primary source of truth. Self-documenting code empowers developers to understand, maintain, and modify codebases more efficiently, ultimately contributing to a higher quality software product. This practice is crucial for everyone involved in software development, from Data Scientists analyzing code to Engineering Managers overseeing projects.

Self-documenting code relies heavily on descriptive and unambiguous naming. Instead of using abbreviated or generic names like val or calc(), opt for descriptive names like userAccountBalance or calculateMonthlyPayment(). This immediately clarifies the purpose of the variable or function, reducing the need for additional comments. Maintaining consistent naming conventions across the entire codebase further enhances readability and allows developers to quickly grasp the role of different code elements.
A well-structured and organized codebase is also key to self-documenting code. Employing a logical structure, such as grouping related functions within modules or classes, and adhering to the principle of separation of concerns, where each part of the code focuses on a specific task, helps to tell the story of the code's purpose. This organized structure facilitates easy navigation and comprehension, making it simpler for developers – be they Software Engineers, Mobile Engineers (Android/iOS), or even IT Analysts – to understand the flow and logic of the code.
The benefits of writing self-documenting code are numerous. It significantly reduces the maintenance overhead associated with keeping documentation up-to-date. When code changes, the documentation automatically stays in sync. This improved readability also makes code reviews more efficient and facilitates faster onboarding for new team members, including those transitioning into roles like DevOps Engineer, Cloud Engineer, or DevEx Engineer.
However, it's important to acknowledge the potential drawbacks. Descriptive names can sometimes lead to longer variable and function names. Achieving true self-documentation can be challenging for particularly complex algorithms, and high-level architectural decisions might still require some form of external documentation, particularly for public APIs.
For example, Google's code style guides emphasize self-documenting practices, and companies like Netflix and Spotify have successfully implemented Clean Code principles, which advocate for self-documenting code. These real-world examples demonstrate the effectiveness of this practice across various software development contexts. For a deeper look at these principles and practical applications, Learn more about Write Self-Documenting Code.
Here are some actionable tips to write self-documenting code:
- Intention-Revealing Names: Use names that clearly express the purpose of variables, functions, and classes.
- Avoid Abbreviations and Cryptic Naming: Opt for clarity over brevity, especially when working on collaborative projects.
- Small and Focused Functions: Break down complex tasks into smaller, more manageable functions, each responsible for a single operation. This enhances readability and makes it easier to understand the role of each function.
- Use Enums Instead of Magic Numbers: Replace hardcoded numeric values with descriptive enums to improve code clarity and maintainability.
- Logical Code Organization: Organize code into modules and classes based on functionality and purpose. Establish clear module boundaries to improve code structure and navigation.
Self-documenting code, championed by figures like Robert C. Martin (Uncle Bob) in his book "Clean Code," Martin Fowler in his work on Refactoring, and Kent Beck with Extreme Programming practices, is a cornerstone of efficient and maintainable software development. While not a complete replacement for all documentation, it's a powerful technique that streamlines the development process and empowers teams to build higher quality software. By focusing on clarity and expressiveness within the code itself, developers can create software that is not only functional but also inherently understandable and maintainable, which is crucial for everyone from Computer Science Teachers explaining concepts to Risk and Compliance officers auditing code.
2. Maintain Comprehensive API Documentation
In the interconnected world of software development, Application Programming Interfaces (APIs) serve as the crucial bridges connecting different systems. For these bridges to be effectively utilized, clear and comprehensive documentation is paramount. Maintaining comprehensive API documentation is a cornerstone of code documentation best practices, facilitating seamless integration, reducing developer friction, and promoting wider adoption of your API. This practice involves meticulously detailing every aspect of your API, including endpoints, parameters, response formats, authentication methods, and usage examples. It acts as the primary reference for developers, whether internal or external, who are integrating with or consuming the API. This detailed guide helps ensure proper implementation, minimizes integration time, and significantly reduces the need for support requests. Effective API documentation is not just a helpful addition; it's a critical component of a successful API strategy.

A well-documented API should include several key features: complete endpoint documentation with supported HTTP methods (GET, POST, PUT, DELETE, etc.); detailed parameter specifications with their types, constraints, and whether they are required or optional; clear examples of response formats, including success responses and potential error codes; comprehensive explanation of authentication and authorization requirements; and, ideally, interactive testing capabilities allowing developers to experiment with the API directly within the documentation. Providing code examples in multiple programming languages further enhances the accessibility and usability of the documentation.
The benefits of maintaining comprehensive API documentation are numerous. It enables faster integration by external developers, reducing the time and effort required to understand and utilize the API. This, in turn, reduces support tickets and developer confusion, freeing up valuable resources. Clear and accessible documentation facilitates broader API adoption and ecosystem growth, as developers are more likely to integrate with an API that is easy to understand and use. Furthermore, it provides a clear contract between API providers and consumers, outlining the expected behavior and functionality of the API. This clarity also supports automated testing and validation, allowing developers to verify their integrations against the documented specifications.
However, creating and maintaining comprehensive API documentation isn't without its challenges. It requires a significant time investment, both initially and ongoing. API documentation can become outdated quickly if not properly maintained, especially in rapidly evolving projects. It may also require specialized tools and expertise, such as knowledge of API documentation generators like Swagger or OpenAPI. This adds an additional overhead to the development process, but the long-term benefits significantly outweigh the initial investment.
Several successful implementations demonstrate the power of comprehensive API documentation. Stripe's API documentation, known for its interactive examples, allows developers to experiment with API calls directly within the documentation. GitHub's REST API documentation provides comprehensive endpoint coverage, ensuring developers have access to all the information they need. Twitter API v2 documentation offers detailed authentication flows, crucial for secure API access. Slack's API documentation stands out with its SDK examples, simplifying integration for developers using various programming languages.
To ensure your API documentation is effective and up-to-date, consider these tips: Use tools like Swagger/OpenAPI for automated documentation generation, minimizing manual effort and ensuring consistency. Include practical code examples for common use cases, demonstrating how to use the API in real-world scenarios. Provide sandbox environments for testing, allowing developers to experiment without affecting production data. Keep documentation updated with every API change, ensuring accuracy and preventing integration issues. Crucially, include rate limiting and error handling information, providing developers with the knowledge they need to handle potential issues effectively. The effort invested in maintaining excellent API documentation, like that championed by the Swagger/OpenAPI Specification team, Postman, Stripe, and Twilio, is a direct investment in the success and adoption of your API.
3. Use Inline Comments Strategically
Inline comments are a crucial element of code documentation best practices, serving as concise explanations directly within the codebase. They offer immediate context and insights into the "why" behind specific code decisions, augmenting the "what" that is often self-evident from the code itself. Used strategically, inline comments enhance code maintainability, facilitate debugging, and preserve valuable institutional knowledge. However, overuse or improper implementation can lead to clutter and outdated information, negating their benefits.
Strategic inline commenting involves judiciously placing comments within the code to elucidate complex logic, intricate business rules, or non-obvious implementations. Unlike comprehensive documentation which provides a high-level overview, inline comments focus on the nuances and rationale behind particular lines or blocks of code. They bridge the gap between what the code does and why it does it that way. This is especially valuable for future maintainers, including yourself, who may not immediately grasp the reasoning behind past decisions.
For example, imagine a complex algorithm within a data science project. The code might perform a series of transformations on a dataset. While the individual operations might be understandable, the overall purpose or the specific reason for choosing a particular method might not be obvious. A well-placed inline comment can explain the underlying statistical principle being applied or the business requirement that necessitates this transformation, making the code significantly more understandable. Similarly, in system administration scripts, an inline comment can explain a specific workaround employed for a particular operating system quirk, preventing future confusion and potentially disastrous modifications.
Examples of Successful Implementation:
- Linux kernel comments: These often explain hardware-specific implementations, providing essential context for driver developers.
- Financial software comments: Inline comments in financial applications can clarify regulatory compliance requirements related to specific calculations or data handling procedures.
- Game engine comments: Comments can explain optimization techniques applied to critical rendering loops or physics calculations, helping other developers understand and maintain performance.
- Cryptographic library comments: Security considerations and the rationale behind specific cryptographic choices are often documented inline to ensure secure implementation and avoid vulnerabilities.
Actionable Tips for Effective Inline Commenting:
- Focus on "why," not "what": Avoid redundant comments that merely restate the code's function. Instead, explain the reasoning behind the code. For example, instead of "// This loop iterates over the array," write "// This loop iterates over the array to find the maximum value for input validation."
- Comment complex algorithms and business rules: These areas often require deeper understanding and benefit greatly from clear explanations.
- Update comments when modifying related code: Ensure comments remain consistent with the code. Outdated comments can be more misleading than no comments at all.
- Use TODO comments for future improvements: Mark areas for future work or refactoring with TODO comments, making it easy to track and address technical debt.
- Avoid obvious comments that restate the code: These clutter the codebase and provide no real value.
Pros and Cons of Inline Comments:
Pros:
- Provides immediate context while reading code
- Helps explain business logic and requirements
- Assists in debugging and troubleshooting
- Preserves institutional knowledge
- Reduces time needed to understand complex sections
Cons:
- Can become outdated and misleading if not maintained
- May indicate overly complex code that needs refactoring
- Can clutter code if overused
- Requires maintenance alongside code changes
When and Why to Use Inline Comments:
Inline comments are most effective when used to:
- Explain complex algorithms or logic that isn't readily apparent.
- Clarify business rules and their impact on the code.
- Document temporary workarounds or hacks with an explanation for their existence.
- Provide context for future maintainers (including your future self).
- Explain regulatory or compliance requirements relevant to specific code sections.
Using inline comments strategically is a critical component of code documentation best practices. It elevates code from a series of instructions to a comprehensible narrative, fostering collaboration, maintainability, and long-term project success. Learn more about Use Inline Comments Strategically Effective inline commenting contributes significantly to a well-documented and maintainable codebase, saving time and resources in the long run. This is especially crucial for teams composed of data scientists, system administrators, DevOps engineers, and other technical roles where understanding the “why” behind the code is essential for effective collaboration and maintenance. This also assists engineering managers, agile coaches, product managers, and those involved in risk and compliance to understand the rationale and implications of specific code implementations. Finally, clear and concise commenting promotes best practices amongst computer science teachers and IT analysts, ensuring the next generation of developers understands the importance of well-documented code.
4. Create and Maintain README Files
README files are the unsung heroes of software projects, acting as the welcoming committee for anyone encountering your code. They provide a crucial first impression and offer a roadmap to understanding and interacting with the project. Whether you're building a small utility script or a complex distributed system, a well-written README significantly impacts a project's success, facilitating collaboration, boosting adoption, and saving both developers and users valuable time. It forms a critical part of your overall code documentation best practices, ensuring your project is easily discoverable, understandable, and contributable.

A README typically resides in the root directory of a project and is often the first file someone reads. It serves as a central hub of information, explaining the project's purpose, installation instructions, usage examples, and how to contribute. Think of it as a comprehensive guide that helps others quickly grasp the essence of your project without needing to dive into the code itself. This is particularly crucial for open-source projects, where a compelling README can significantly increase community engagement and attract contributions.
A comprehensive README typically incorporates the following key features: a clear and concise project description and purpose statement; step-by-step installation and setup instructions; practical usage examples and basic tutorials; guidelines for contributing to the project, including development setup; license information and credits; and badges displaying build status, version information, and other relevant metrics. This rich set of information ensures that anyone, from a seasoned developer to a curious user, can quickly get acquainted with your project.
The benefits of maintaining a high-quality README are numerous. They improve project discoverability and adoption rates by providing potential users with a clear understanding of the project's value proposition. They significantly reduce the barrier to entry for new contributors, making it easier for others to get involved and contribute effectively. A well-structured README provides a quick project overview without requiring a deep dive into the codebase, saving time and effort for everyone involved. Moreover, a polished README enhances the professional appearance of the project, reflecting attention to detail and commitment to quality. Finally, it serves as a form of living documentation that stays with the code, ensuring that critical information remains readily accessible throughout the project's lifecycle.
However, like any form of documentation, READMEs come with their own set of potential drawbacks. They can become lengthy and overwhelming if not carefully organized, making it difficult for readers to find the information they need. They require regular updates to stay current with the project's evolution, which can be challenging for busy developers. There is also a risk of duplicating information found elsewhere in the project's documentation, leading to inconsistencies and potential confusion. Finally, the quality of READMEs can vary significantly across projects, ranging from meticulously crafted guides to bare-bones descriptions, highlighting the importance of prioritizing README maintenance and adhering to code documentation best practices.
Successful implementations of READMEs can be found in popular open-source projects like React.js, TensorFlow, Bootstrap, and Vue.js. React's README, for instance, offers clear installation and usage examples, making it easy for developers to get started quickly. TensorFlow's README provides a comprehensive getting started guide, catering to users with varying levels of expertise. Bootstrap's README includes CDN links and basic usage examples, facilitating quick integration into web projects. Vue.js's README presents an ecosystem overview and links to learning resources, supporting users in their journey to master the framework. These examples demonstrate the versatility and power of well-crafted READMEs in driving project adoption and community engagement.
To create effective READMEs, start with a clear, concise, one-sentence project description that captures the essence of your work. Include a quick start section that provides immediate value and allows users to experience the project's core functionality without delay. Use screenshots or GIFs to demonstrate functionality visually, enhancing understanding and engagement. Keep installation instructions up-to-date and thoroughly tested to avoid frustration for new users. Include links to more detailed documentation for those who need to delve deeper into specific aspects of the project. For longer READMEs, add a table of contents for improved navigation and discoverability. By following these code documentation best practices, you can ensure that your README serves as a valuable resource for anyone interacting with your project.
5. Generate Documentation from Code
Keeping code documentation up-to-date can be a significant challenge in any software project. As code evolves, documentation can quickly become outdated, leading to confusion for developers, system administrators, and anyone else interacting with the codebase. One of the most effective code documentation best practices is to generate documentation directly from the source code itself. This automated approach offers a powerful way to ensure consistency, reduce manual effort, and keep documentation in sync with the latest code changes, making it an essential tool for data scientists, DevOps engineers, software engineers, and anyone involved in the software development lifecycle.
Automated documentation generation leverages tools that parse your source code, extracting information like function signatures, parameter types, return values, and specially formatted comments. These tools then process this extracted information and transform it into a structured, readable format, such as HTML, PDF, or Markdown. This method allows the documentation to live alongside the code, ensuring easy access and a single source of truth for everyone involved. By adhering to this best practice, engineering managers and agile coaches can foster a culture of well-documented code, promoting maintainability and collaboration within their teams.
Here's a deeper dive into the benefits and considerations of this approach:
How it Works:
The core principle of automated documentation generation revolves around embedding documentation within the code itself. This is typically achieved through specially formatted comments, often referred to as "docstrings" or "doc comments." These comments adhere to a specific syntax recognized by the documentation generator tool. For example, Javadoc for Java, JSDoc for JavaScript, Sphinx for Python with reStructuredText, and Doxygen for C++ all utilize unique comment formats. These comments often contain detailed descriptions of the code's functionality, parameters, return types, and even usage examples. The tools then parse these comments and generate output in a desired format.
Features & Benefits:
- Automatic Extraction of Function Signatures and Parameters: Documentation generators automatically extract function signatures, parameter types, and return values, eliminating the need to manually document this crucial information, which is especially helpful for languages like Java or C++ with complex method signatures.
- Integration with Specially Formatted Code Comments: This integration enables developers to write documentation directly within the code, reducing context switching and making it easier to keep documentation up-to-date.
- Support for Multiple Output Formats: Most tools support generating documentation in various formats like HTML, PDF, and Markdown, offering flexibility for different use cases. This makes sharing documentation with different teams, such as product managers or IT analysts, more streamlined.
- Cross-referencing Between Related Code Elements: Advanced tools like Doxygen allow cross-referencing between different parts of the codebase, making it easy to navigate and understand relationships between different modules and classes. This feature is particularly useful for cloud engineers and system administrators working with complex, distributed systems.
- Integration with Continuous Integration Pipelines: Integrating documentation generation into CI/CD pipelines ensures that documentation is automatically updated with every code change, making documentation a seamless part of the development workflow and reducing the risk of documentation becoming stale. This automated approach greatly benefits DevOps engineers and DevEx engineers striving for streamlined processes.
Pros and Cons:
Pros:
- Ensured Synchronization: Keeps documentation in sync with the codebase.
- Reduced Manual Effort: Minimizes the need for manual documentation updates.
- Consistent Formatting and Structure: Enforces a consistent style and structure across the entire documentation.
- Seamless Integration with Development Workflows: Easily integrates into CI/CD pipelines and existing development processes.
- Multilingual Support: Many tools support multiple programming languages.
Cons:
- Limited to Code-Extractable Information: Can't capture high-level architectural concepts or design decisions that aren't explicitly present in the code.
- Potential for Verbose or Cluttered Output: May require careful comment formatting to avoid overly verbose or cluttered documentation.
- Learning Curve: Requires developers to learn the specific comment formatting syntax used by the chosen tool.
- Developer Discipline: Relies on developers consistently writing detailed and informative comments.
Examples:
- Javadoc (Java): Generates HTML documentation from Java source code using specifically formatted comments.
- Sphinx (Python): Uses reStructuredText to create comprehensive documentation for Python projects.
- JSDoc (JavaScript): Generates API documentation from JavaScript code using a specific comment syntax.
- Doxygen (C++): Creates cross-referenced documentation from C++ code, also supporting other languages.
Tips for Effective Automated Documentation:
- Consistency is Key: Use consistent comment formatting throughout the project.
- Detailed Descriptions: Include thorough parameter descriptions, return value explanations, and potential exception details.
- Illustrative Examples: Add usage examples in documentation comments to demonstrate how to use functions or classes.
- Style Configuration: Configure generation tools to match your project's coding style and documentation preferences.
- CI/CD Integration: Integrate documentation generation into your CI/CD pipeline for automatic updates.
By embracing automated documentation generation, development teams can significantly improve the quality, consistency, and maintainability of their code documentation, a critical aspect of any successful software project. This code documentation best practice, when implemented effectively, provides significant value to all stakeholders, from individual developers to product managers, ensuring that everyone has access to accurate, up-to-date information about the codebase.
6. Document Architecture and Design Decisions
Among the most crucial code documentation best practices is documenting architecture and design decisions. This involves creating a record of the rationale behind significant architectural choices made during a software project's lifecycle. These records, often called Architecture Decision Records (ADRs), serve as a valuable resource for understanding the "why" behind the "what" of a system's design. This practice goes beyond merely documenting how the system works and delves into why it works that way, capturing the thought process, the options considered, and the reasons for choosing a particular path. This is critical for maintaining institutional knowledge, facilitating collaboration, and enabling informed future development. This deserves its place in the list of best practices because it addresses the often-overlooked aspect of design rationale, which is crucial for long-term project health and team effectiveness.
ADRs typically follow a structured format, capturing the context of the decision, the problem being addressed, the various solutions explored, and the justifications for the chosen solution. They also include details about the anticipated consequences and trade-offs of the decision, along with information about who made the decision and when. This structured approach ensures consistency and makes the information readily accessible.
Features of effective architecture decision documentation include:
- Structured Format: Consistent structure allows for easy navigation and comparison of different decisions.
- Context and Problem Statement: Clearly defines the situation that prompted the decision.
- Alternative Solutions Considered and Rejected: Demonstrates a thorough evaluation process.
- Consequences and Trade-offs: Highlights the potential impacts of the chosen approach.
- Timeline and Decision Ownership: Provides accountability and historical context.
Several organizations have successfully implemented ADRs. Netflix, for example, uses ADRs extensively to document decisions related to their microservices architecture. Similarly, Spotify's engineering culture emphasizes documentation, including ADRs, to facilitate knowledge sharing and collaboration. GitHub also leverages ADRs for platform architecture decisions, ensuring transparency and maintainability. Even governmental digital services are adopting ADRs for greater transparency and accountability.
Implementing architecture decision documentation offers several benefits:
- Preserves Institutional Knowledge: Captures the rationale behind decisions that might otherwise be lost over time or with personnel changes.
- Onboarding: Helps new team members quickly understand the system's design and the reasons behind specific choices.
- Facilitates Future Changes: Provides a foundation for making informed decisions about architectural evolution, avoiding unintended consequences.
- Reduces Repeated Discussions: Prevents revisiting already-settled decisions, saving time and effort.
- Audit Trail: Creates a record of decisions for compliance and governance purposes.
However, there are some potential drawbacks to consider:
- Maintenance Overhead: Requires time and effort to create and keep ADRs up-to-date.
- Risk of Obsolescence: ADRs can become outdated if not regularly reviewed and updated.
- Potential for Bureaucracy: Overly formal processes can stifle agility.
- Reliance on Team Discipline: Effectiveness depends on team members consistently creating and maintaining ADRs.
To effectively implement ADRs, consider the following tips:
- Lightweight Templates: Use simple, easy-to-use templates to minimize the overhead.
- Version Control: Store ADRs in version control alongside the code, ensuring they evolve with the system.
- Regular Reviews: Review and update ADRs during architecture reviews and other relevant meetings.
- Visualizations: Include diagrams and other visual representations to enhance understanding.
- Linking: Link ADRs to related code and documentation to create a cohesive knowledge base.
The following infographic visualizes the core components of an Architecture Decision Record:
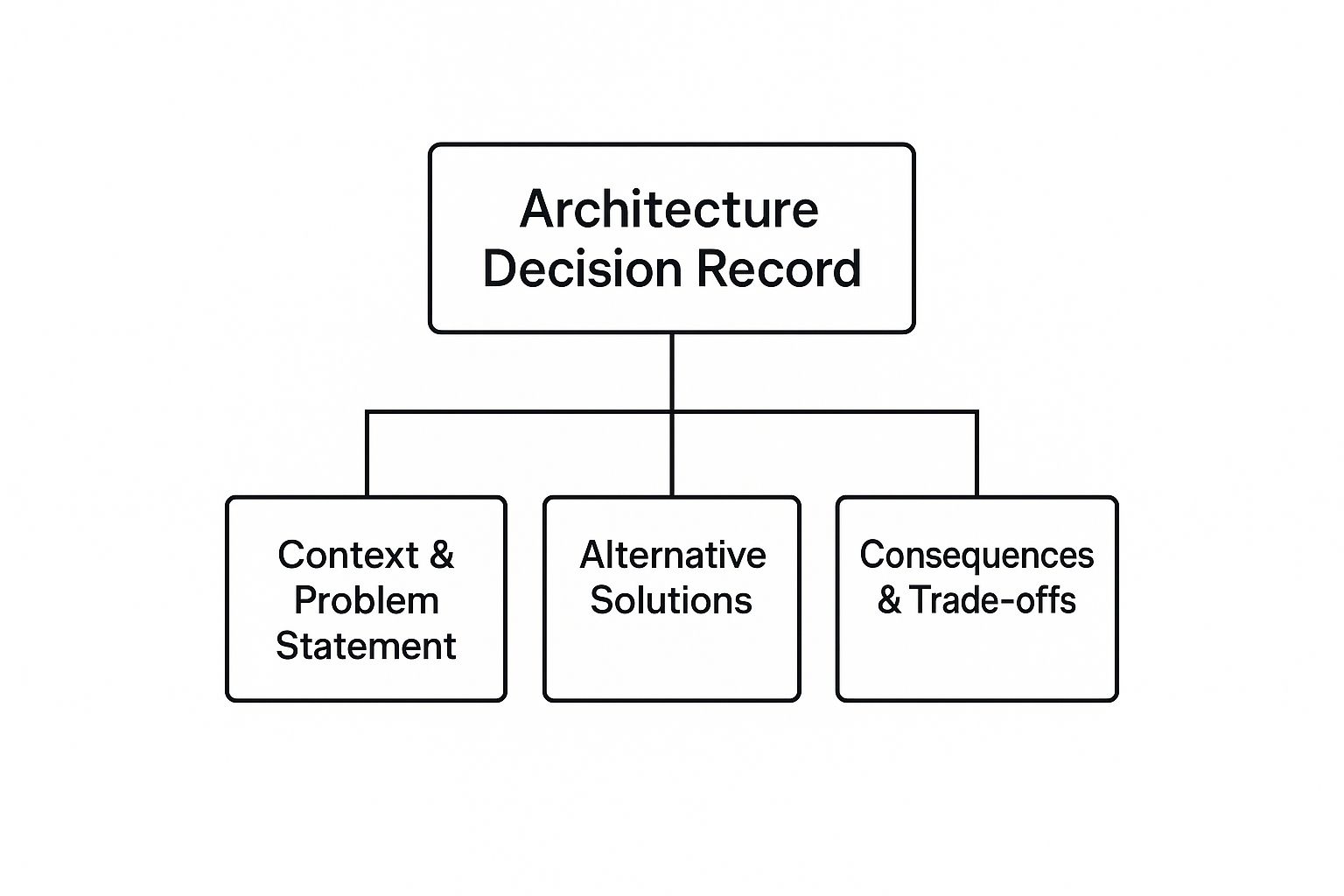
This hierarchical diagram clearly illustrates the three key parts of an ADR: understanding the context and problem, exploring alternative solutions, and evaluating the consequences and trade-offs of the chosen solution. These components ensure a well-rounded and justified architectural decision.
By adopting the practice of documenting architecture and design decisions using ADRs, development teams can build more robust, maintainable, and understandable systems. This practice contributes significantly to code documentation best practices, enabling effective knowledge sharing, collaboration, and informed decision-making throughout a project's lifecycle. The concept of ADRs was popularized by Michael Nygard and has gained significant traction through platforms like the ThoughtWorks Technology Radar and within enterprise architecture communities.
7. Keep Documentation Close to Code
One of the most effective code documentation best practices is to keep your documentation close to your code. This approach, often referred to as "docs as code," involves storing documentation within the same repository as the source code and treating it with the same level of importance. By integrating documentation into the development workflow, teams foster better synchronization between code and its explanation, simplifying maintenance, and enhancing developer collaboration. This practice ensures that documentation evolves alongside the code, reducing the risk of outdated or inaccurate information.
This strategy leverages the same tools and workflows used for code management, making documentation a first-class citizen in the development process. Think of your documentation as another crucial piece of the software, subject to the same rigorous version control, review processes, and deployment procedures as the code itself. This methodology fosters a culture where documentation is an integral part of development, not an afterthought.
How It Works:
The core principle is to store documentation files, typically in Markdown format, alongside the source code within the version control system (e.g., Git). This allows for:
- Version Control: Track documentation changes alongside code modifications, enabling easy rollback and historical analysis.
- Code Reviews: Integrate documentation updates into the standard code review process, ensuring accuracy and consistency.
- Automated Deployment: Deploy documentation updates automatically with code changes, maintaining synchronization and reducing manual effort.
- Branching and Merging: Apply the same branching and merging strategies used for code to manage documentation updates efficiently.
Examples of Successful Implementation:
Several organizations have successfully adopted this approach, demonstrating its effectiveness in practice:
- GitLab: A strong proponent of the docs-as-code philosophy, GitLab stores its entire documentation within the same repository as its source code.
- Microsoft's .NET Projects: Microsoft utilizes a similar strategy for .NET documentation, ensuring consistency and accuracy across the platform.
- Kubernetes Project: The Kubernetes project maintains its comprehensive documentation within its main repository, making it easily accessible to developers.
- GitBook Integration with GitHub Repositories: GitBook seamlessly integrates with GitHub, allowing teams to create and maintain documentation directly within their repositories.
Actionable Tips for Implementation:
Here are some practical tips for effectively implementing this best practice:
- Use a
docs/Folder Structure: Organize your documentation within a dedicateddocs/directory in your repository for clarity and maintainability. - Include Documentation Changes in Pull Request Requirements: Make documentation updates a mandatory part of pull requests to enforce consistency and prevent outdated documentation.
- Set up Automated Documentation Site Generation: Automate the process of generating a documentation website from your Markdown files using tools like Jekyll, Hugo, or Sphinx.
- Use Markdown for Better Version Control Diff Viewing: Markdown's plain-text format allows for easy comparison of changes in version control systems, facilitating efficient review processes.
- Implement Documentation Linting in CI Pipelines: Integrate documentation linting tools into your continuous integration (CI) pipelines to ensure adherence to style guides and identify potential issues early.
Pros and Cons:
Pros:
- Documentation changes are tracked with code changes.
- Easier to keep documentation synchronized with code.
- Documentation benefits from code review processes.
- Single source of truth for project information.
- Improved developer workflow integration.
Cons:
- May clutter code repositories with documentation files.
- Non-technical stakeholders may have difficulty accessing or contributing to documentation within a code repository.
- Requires developers to think about documentation during coding.
- May need additional tooling for documentation presentation and formatting.
When and Why to Use This Approach:
This approach is particularly beneficial for projects with a strong development focus and where accurate, up-to-date documentation is critical. It is especially well-suited for:
- Open-source projects: Facilitates community contributions to documentation.
- API documentation: Ensures documentation aligns with code changes.
- Projects with frequent code updates: Keeps documentation in sync with rapidly evolving codebases.
Learn more about Keep Documentation Close to Code
By adopting the practice of keeping documentation close to code, development teams can foster a culture of documentation as a vital part of the software development lifecycle. This results in higher quality documentation, improved developer experience, and a more maintainable and understandable codebase. This approach is a cornerstone of modern code documentation best practices and should be considered a crucial element of any robust development workflow.
7 Best Practices Comparison
| Best Practice | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ | |----------------------------------|------------------------------------|-----------------------------------|---------------------------------------------------|---------------------------------------------------|--------------------------------------------------| | Write Self-Documenting Code | Medium - requires discipline and careful naming | Low - no special tools needed | Clear, readable code reducing maintenance overhead | Daily coding, complex projects needing long-term maintainability | Improves readability and onboarding, reduces doc sync issues | | Maintain Comprehensive API Documentation | High - requires dedicated effort and tooling | Medium - uses specialized tools like Swagger | Faster integration, fewer support tickets | Public APIs, SDKs, platforms with external developers | Enables ecosystem growth, clear API contracts | | Use Inline Comments Strategically | Low to Medium - depends on code complexity | Low - manual effort | Better understanding of 'why' behind code | Complex algorithms, business logic, regulatory code | Preserves context, aids debugging and comprehension | | Create and Maintain README Files | Low - straightforward but requires upkeep | Low - markdown and basic tools | Improved project adoption and contribution | Open source projects, new repositories | Enhances project visibility and contributor experience | | Generate Documentation from Code | Medium - need to learn/comment well | Medium - tooling setup and maintenance | Synchronized, consistent docs with code | API libraries, multi-language projects | Reduces manual upkeep, consistent output | | Document Architecture & Design Decisions | Medium to High - formal process needed | Medium - time investment | Clear decision rationale, easier future changes | Large, evolving systems, regulated projects | Preserves institutional knowledge, reduces repeated discussions | | Keep Documentation Close to Code | Medium - requires process integration | Low to Medium - tooling for docs site | Well-synced docs and code, smoother workflows | Teams valuing docs-code integration | Single source of truth, improved update synchronization |
Supercharge Your Workflow with Pull Checklist
Mastering code documentation best practices is crucial for any software development team. From writing self-documenting code and maintaining comprehensive API documentation to using inline comments strategically and generating documentation directly from your code, each practice plays a vital role in creating maintainable, scalable, and collaborative projects. Remember the importance of keeping your documentation close to the code itself and documenting key architecture and design decisions to ensure long-term project health. These practices not only improve code readability and reduce onboarding time for new team members, but also contribute significantly to reducing technical debt and fostering a more efficient development lifecycle. For further insights and practical tips, check out this comprehensive guide on documentation best practices to elevate your documentation game even further. This resource, "Top Documentation Best Practices for 2025" from Whisperit, provides valuable insights to help you stay ahead of the curve.
By diligently applying these code documentation best practices, you are investing in the future success of your projects and empowering your team to work smarter, not harder. Now, take your documentation workflow to the next level with Pull Checklist. This GitHub Marketplace app helps enforce your code documentation best practices directly within your pull requests, using customizable checklist templates to guarantee thorough reviews. Streamline your workflow and ensure consistent high-quality documentation with Pull Checklist today!